ZIO Kafka with transactions - a debugging story
Posted on June 15, 2022
Introduction
With one of our clients, we were working on a chain of services responsible for processing some logs coming from a Kafka topic, partition them by some properties like user and date, infer and aggregate the log schema and eventually store the partitioned data in a different format. The details of this use case are not important for understanding this post, in which I'm going to explain the recent changes to ZIO Kafka, how was it implemented and how did we know it's not perfect, and the long story of investigation that finally resulted in a fix making this new feature usable in production.
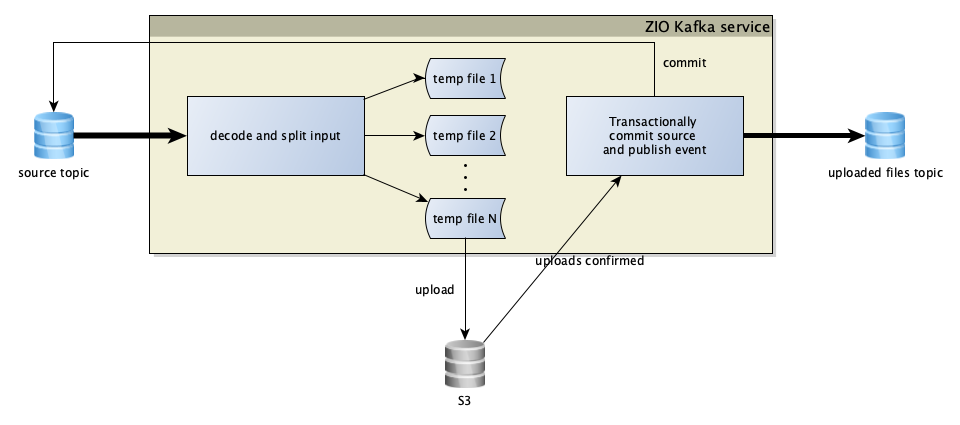
We only have to know about the first component of this data pipeline, which is a zio-kafka service:
- Consumes it's source topic. Each record in this topic consists one or more log entries for a given user. The kafka topic's partitions are not aligned with our target partition (of user/date), all kafka partitions may contain data from all users.
- The service partitions the source data per user/date/hour and writes the log entries into Avro files in the local file system
- It also computes and aggregates a log schema in memory for each of these files
- It is using Kafka transactions to achieve exactly-once delivery. This means that the processed records are not committed when they are written to the Avro files - there is a periodic event triggered every 30 seconds and at each rebalance that uploads the Avro files to S3, and then it emits Kafka messages to downstream containing references to the uploaded files and their aggregated schema, and it commits all the offsets of all the input Kafka topic's transactionally.
Stream restarting mode in zio-kafka
When we first implemented this using zio-kafka and started to test it we have seen a lot of errors like
Transiting to abortable error state due to org.apache.kafka.clients.consumer.CommitFailedException: Transaction offset Commit failed due to consumer group metadata mismatch: Specified group generation id is not valid."}
Group generation ID is a counter that gets incremented at each rebalance. The problem was that zio-kafka by default provides a continuous stream for partitions that survives rebalances. So we have a single stream per Kafka partition and after a rebalance we end up with some of them revoked and their streams stopped, some new streams created, but the ones that remained assigned are not going to be recreated.
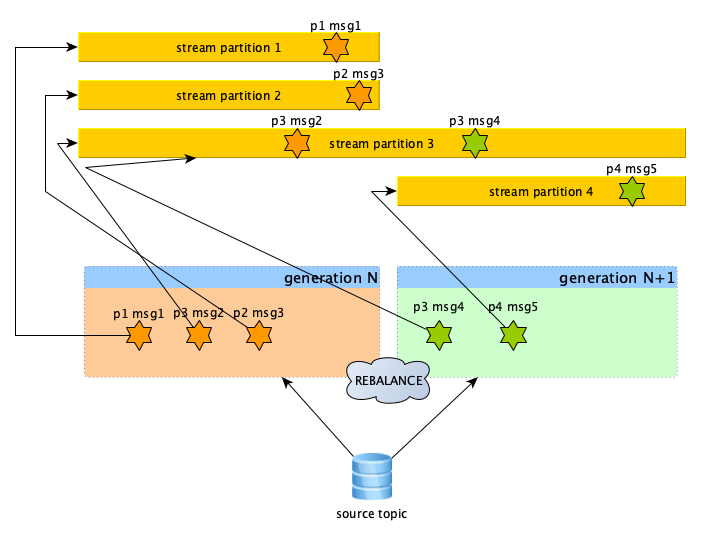
This works fine without using transactions, but it means your stream can contain messages from multiple generations. I first tried to solve this by detecting generation switches downstream but quickly realized this cannot work. It's too late to commit the previous generation when there are already records from the new generation; we have to do it before the rebalance finishes.
To solve this I introduced a new mode in zio-kafka back in February 2022, with this pull request.
This adds a new mode to zio-kafka's core run loop which guarantees that every rebalance stops all the partition streams and create new ones every time.
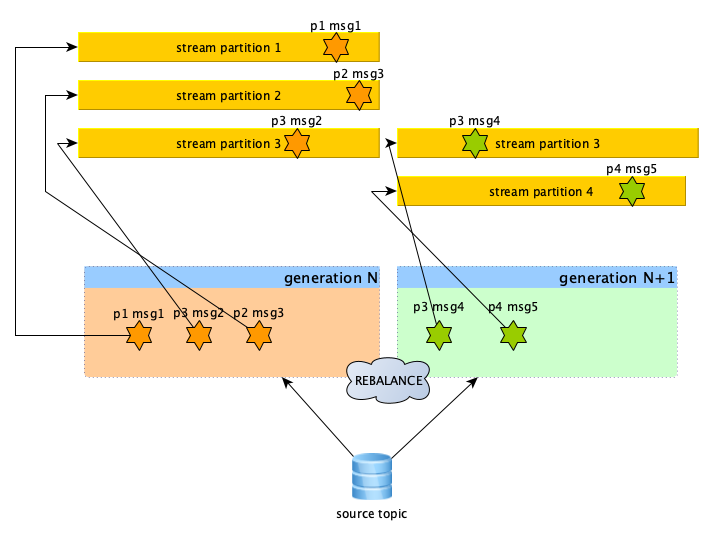
With this approach the library user can build the following logic on top of the "stream of partition streams" API of zio-kafka:
- Get the next set of partition streams
- Merge and drain them all
- Perform a flush - upload and commit everything before start working on the new set of streams
- Repeat
This alone is still not enough - we have to block the rebalancing until we are done with the committing otherwise we would still get the invalid generation ID error.
The onRevoke and onAssigned callbacks from the underlying Java Kafka library are working in a way that they block the rebalance process so that's the place where we can finish every processing for the revoked partitions. This extension point is provided by zio-kafka too but it's completely detached from the streaming API so I have introduced a rebalance event queue with with some promises and timeouts to coordinate this:
- In
onRevokewe publish a rebalance event and wait until it gets processed. - Because the new run loop mode is guaranteed to terminate all streams on rebalance (which is already happening, as we are in
onRevoke) we can be sure that eventually the main consumer stream's current stage - that drains the previous generation's partition streams will finish soon - and then it performs the rotation and fulfills the promise in the rebalance event.
With these changes our service started to work - but we had to know if it works correctly.
QoS tests
We implemented a QoS test running on Spark which periodically checks that we are not loosing any data with our new pipeline.
Our log entries have associated unique identifiers coming from upstream - so what we can do in this test is to consume an hour amount of log records from the same Kafka topic our service is consuming from, and read all the Avro files produced in that period (with some padding of course to have some tolerance for lag) and then see if there are any missing records in our output.
Another source of truth for the investigation was an older system doing something similar, resulting in the same input being available as archived CSV files in some cases. Comparing the archived CSV files with the archived Avro files I could verify that the QoS test itself works correctly, by checking that both methods report the same set of missing records.
What we learned from these tests was that:
- there is data loss
- the data loss is related to rebalances
To understand it's related to rebalances I was comparing failing QoS reports from several hours, figured out the ingestion time for some of the missing log records within these hours, and checked our service and infrastructure logs around that time. Every time there was a rebalance near the reported errors.
Additional tests
During the investigation I added some additional debug features and logs to the system.
One of them is an extra verification step, enabled only temporarily in our development cluster, that
- aggregates all the log identifiers at the earliest point - as soon as they got in the zio-kafka partition stream
- after uploading the Avro files and committing the records, it re-downloads all the files from S3 and checks if they got all the log identifiers that they should.
This never reported any error so based on that I considered the flow after zio-kafka correct.
We also have a lot of debug logs coming from the Java Kafka library, from zio-kafka and from our service to help understanding the issue:
- After each rebalance, the Java library logs the offset it's starting to read from
- When committing I'm logging the minimum and maximum offset contained by the committed and uploaded Avro files per kafka partition
- All streams creation and termination are logged
- If records within a partition stream are skipping an offset (this was never logged actually)
I wrote a test app that reads our service's logs from a given period, logged from all the Kubernetes pods it's running on, and runs a state machine that verifies that all the logged offsets from the different pods are in sync. It fails in two cases:
- When a pod resets its offsets to something that was previously seen in the logs and there is a gap
- When a pod rotates a kafka without it got assigned to that pod first (so if multiple pods would somehow consume the same partition which Kafka prevents)
I tried for long to write integration tests using embedded Kafka (similar to how it's done in zio-kafka's test suite) that reproduces the data loss issue, without any luck. In all my simulated cases everything works perfectly.
Theories and fixes
From logs from the time ranges where the data loss is reported from, these additional checks were not showing any discrepancies.
This could only mean two things:
- All the kafka/zio-kafka level is correct but we are still loosing data in our service-specific logic, somewhere in writing to Avro-s and uploading to S3.
- On Kafka level everything is fine but somehow zio-kafka does not pass all the records to our service's logic
I trusted the validation mode I described earlier (the one that re-downloads the data) so I ruled out the first option.
zio-kafka internals
Before discussing the fixes I tried to make in zio-kafka, first let's talk about how the library works.
The zio-kafka library wraps the Java library for Kafka and provides a ZIO Stream interface for consuming the records. As I mentioned earlier, it creates a separate stream for each kafka partition assigned to the consumer. The primary operation on the Java interface is called poll. This method is responsible for fetching data for all the subscribed partitions for a given timeout. Another important property is that in case of rebalancing, the poll is blocked until the rebalancing completes, and it calls the already mentioned revoked/assigned callbacks in this blocked state.
Another thing it has to support is back pressure. We don't want this poll to fetch more and more data for partitions where we did process the previous records yet. In other words, upstream demand in our ZIO Streams must control what partitions we poll. In the Java level this is controlled by pausing and resuming individual partitions.
So let's see a summary of how the consumer streams work:
- Each partition stream is a repeated ZIO effect that enqueues a
Requestin a queue and then waits for the promise contained in this request to be fulfilled. The promise will contain a chunk of records fetched from Kafka if everything went well. - There is a single (per consumer) run loop which periodically calls
poll. Before calling it, it pauses/resumes partitions based on which partitions has at least oneRequestsince the lastpoll. - This, as ZIO streams are pull based, implements the back pressure semantics mentioned earlier.
There is a similar mechanism for gathering commit requests and then performing them as part of the run loop but in our use case that is not used - the transactional producer is independent of this mechanism.
There is one more concept which is very important for to understand the problem: buffered records. Imagine that we are consuming five partitions, 1 .. 5 and only have a request (downstream pull) for partition 1. This means we are pausing 2 .. 5 and do a poll but what if the resulting record set contains records from other partitions? There could be multiple reason for this (and some of them may not be possible in practice), for example there could be some data already buffered within the Java library for the paused partitions, or maybe a rebalance assigns some new partitions which are not paused yet (as we don't know we are going to get them) resulting in immediately fetching some data for them.
The library handles these cases in a simple way: it buffers these records which were not requested in a per-partition map, and when a partition is pulled next time, it will not only give the records returned by poll to the request's promise, but also all the buffered ones, prepended to the new set of records.
Another important detail for this investigation is that we don't care about graceful shutdown, or if records got lost during shutdown. This is also very interesting in general, but our service is not trying to finish writing and uploading all data during shutdown, it simply ignores the partial data and quits without committing them so they get reprocessed as soon as possible in another consumer.
What happens during rebalancing? Let's forget the default mode of zio-kafka for this discussion and focus on the new mode which restarts all the partition streams every time.
We don't know in advance that a rebalance will happen, it happens during the call to poll. The method in the run loop that contains this logic is called handlePoll and does roughly the following (in our case):
- store the current state (containing the current streams, requests, buffered records etc) in a ref
- pause/resume partitions based on the current requests, as described earlier
- call
poll- during
pollin the revoked callback we end all partition streams. This means they get an interrupt signal and they stop. As I mentioned earlier, in this mode the consumer merges the partition streams and drain them; this is the other side of it, interrupting all the streams so we know that eventually this merged stream will also stop. - dropping all the buffered records, but first adding them to a drain queue (this is a fix that was not part of the original implementation). It is now guaranteed that the partition streams will get the remaining buffered elements before they stop.
- storing the fact of the rebalancing, so the rest of
handlePollknows about it whenpollreturns.
- during
- once
pollreturned, buffer all records for all unrequested partitions. this is another place where a fix was made, currently we treat all records unrequested in case of a rebalancing, because all the streams were restarted, so the original requests were made by the previous set of streams; fulfilling them would loose data because the new streams are not waiting for the same promises. - the next step would be to fulfill all the requests that we can by using the combination of buffered records and the
pollresult. But we had a rebalance and dropped all the requests! So this step must not do anything. - finally we start new streams for each assigned partition
So based on all this, and the theory that the commits/offsets are all correct but somehow data is lost between the Java library and the service logic, the primary suspect was the buffered records.
Let's see what fixes and changes I made, in time order:
Fix attempt 1
The first time I suspected buffered records are behind the issue I realized that when we end all partition streams during rebalancing, we loose the buffered records. This is not a problem if those partitions are really revoked - it means there was no demand for those partitions, so it's just that some records were read ahead and now they get dropped and will be reprocessed on another consumer.
But if the same partition is "reassigned" to the same consumer, this could be a data loss! The reason is that there is an internal state in Kafka which is a per-consumer, per-partition position. In this case this position would point to after the buffered records, so the next poll will get the next records and the previously buffered ones will not be prepended as usual because the revocation clears the buffer.
Note that this whole problem would not exist if the reassigned partitions get reseted to the last committed offset after rebalancing. I don't think this is the case, only when a new partition is assigned to a consumer with no previous position.
My first fix was passing the buffered records to the user-defined revoke handler so it could write the remaining records to the Avro files before uploading them. This was just a quick test, as it does not really fit into the API of zio-kafka.
Fix attempt 2
After playing with the first fix for a while I thought it solved the issue but it was just not reproducing - it is not completely clear why, probably I missed some test results.
But I wrote a second version of the same fix, this time by adding the remaining buffered elements to the end of the partition streams before they stop, instead of explicitly passing them to the revoke handler.
This should work exactly the same but handles the problem transparently.
Fix attempt 3
After some more testing it was clear that the QoS tests were still showing data loss. The investigation continued and the next problem I have found was that in handlePoll after a rebalance we were not storing the buffered records anymore in this "restarting streams" mode. I did not catch this in the first fix attempts I was focusing on dealing with the buffered records at the end of the revoked streams.
What does it mean it was not storing the buffered records? In handlePoll there is a series of state manipulation functions and the buffered records map is part of this state. The logic here is quite complicated and it very much depends on whether we are running the consumer in normal or stream restarting mode. The problem was that for some reason after a rebalance (in the new mode only) this buffered records field was cleared instead of preserving records from before the rebalance.
Fix attempt 4
Very soon turned out that my previous fix was not doing anything, because there was one more problem in the state handling in handlePoll. As I wrote, it bufferes only those records which were not requested. For those partitions which have a request, it fulfills these requests with the new records instead. When the reassigned partitions are not restarted during rebalancing (as in the normal mode) this is OK but for us, as we are creating new streams, the old requests must be dropped and not taken into account when deciding which records to buffer.
In other words, in restarting streams mode we have to buffer all records after a rebalance.
Fix attempt 5
I was very confident about the previous fix but something was still not OK, the test continued to report data loss. After several code reviews and discussions, I realized that it is not guaranteed that the onRevoked and onAssigned callbacks are called within a single poll! My code was not prepared for this (the original zio-kafka code was, actually, but I did not realize this for a long time).
First of all I had to change the way how the rebalance callbacks are passing information to the poll handler. The previously added rebalance event (which was a simple case class) was changed to be either Revoked, Assigned or RevokedAndAssigned and I made sure that for each case all the run loop state variables are modified correctly.
Immediately after deploying this, I saw evidence in the logs that indeed the revoked and assigned callbacks are called separately, so the fix was definitely needed. The only problem was that I did not really understand how could this cause data loss, and by doing some rebalancing tests it turned out that the problem still exists.
Fix attempt 6
One more thing I added in the previous attempt was a log in a place that was suspicious to me and I did not care about it earlier. When adding requests to the run loop - these are added to the run loop's command queue when a partition stream tries to pull, completely asynchronous to the run loop itself - it was checking if currently the run loop is in the middle of a rebalancing. So in case the rebalancing takes multiple polls, as we have seen, it is possible that between the onRevoked and onAssigned events we get some new requests from the streams.
In the restart-streams mode all partition streams are interrupted on the revoke event, and no new streams are created until the assigned event. This means that these requests can only come from the previous streams so they should be ignored. But what zio-kafka was doing was to add these requests to the run loop's pending requests. This is correct behavior in its normal mode, because on rebalance some of the streams survive it and their requests can be still fulfilled.
But in our case it is incorrect, because after the assignment is done and some records are fetched by poll, these pending requests get fulfilled with them, "stealing" the records from the new partition streams!
At this point I really felt like this was the last missing piece of the puzzle.
Conclusion
And it was!
The final set of fixes are published in this pull request. The service and its tests are running perfectly since more than 10 days, proving that it is correct.